JPselect: Just-Pope Production Functions with Heckman Selectivity
Overview
JPselect is an R package that implements the three-step estimation procedure of Koundouri & Nauges (2005) for Just-Pope (1978, 1979) stochastic production functions with sample-selection bias from crop choice. The package bundles the probit selection equation, the linear-quadratic mean function with an Inverse Mills Ratio, the Cobb-Douglas risk (variance) function, and a full-pipeline bootstrap, behind a single high-level interface.
Code, documentation, and a runnable example are available on GitHub. Install with remotes::install_github("robcareta/JPselect").
The problem it solves
When farmers choose what to grow, that choice depends on characteristics (soil quality, water access, farming experience) that also affect productivity. Estimating a production function on the chosen sub-sample, for example just the vegetable growers, mixes the technological relationship between inputs and output with the self-selection of farms into crops. The result is biased estimates of how inputs affect both mean output and its variability.
Koundouri and Nauges’ main finding is that skipping the Heckman correction can flip the sign or kill the significance of risk-function coefficients. An applied researcher who reports the naive estimates can therefore reach the wrong conclusion about which inputs are risk-increasing or risk-decreasing.
JPselect runs both the corrected and uncorrected specifications and shows them side by side, so the bias is visible directly.
What’s inside
The package exposes a small surface area:
| Function | Purpose |
|---|---|
jp_fit() |
One-call wrapper for the full three-step pipeline plus the with-vs-without comparison. Returns a jpfit S3 object. |
print(fit) |
Risk-function table plus a plain-language interpretation: which inputs are risk-increasing or decreasing, where selectivity correction changes the conclusion, whether the Mill’s ratio is significant. |
summary(fit) |
All three stages of the procedure end-to-end: probit, mean function with Mill’s ratio, with vs. without risk function. |
plot(fit) |
Headline coefficient plot of the risk function. |
jp_export() |
Writes the four resulting tables to Excel (one workbook, five sheets), LaTeX (booktabs tables for a paper), or CSV (one file per table). |
simulate_kiti_data() |
Synthetic 239-farm dataset that mimics the paper’s Cyprus sample, for demonstration and testing. |
Individual stage functions (estimate_selection, estimate_mean_function, estimate_risk_function) are also exported for users who want finer control.
Sample output
print(fit) ends with a structured interpretation block:
At p < 0.10, with selectivity correction:
Risk-DECREASING inputs : (none)
Risk-INCREASING inputs : (none)
Does selectivity correction change the conclusion?
labor : significant without correction (p=0.022) but NOT significant once corrected (p=0.116)
water : significant without correction (p=0.030) but NOT significant once corrected (p=0.519)
Selection-bias test (Mill's ratio in the mean function):
coef = +0.527, p = 0.036 -- selection bias DETECTED.
Prefer the 'with correction' column above.The headline plot shows each input twice (red = with selectivity correction, teal = without). When the two estimates disagree, the selectivity bias is visible at a glance:
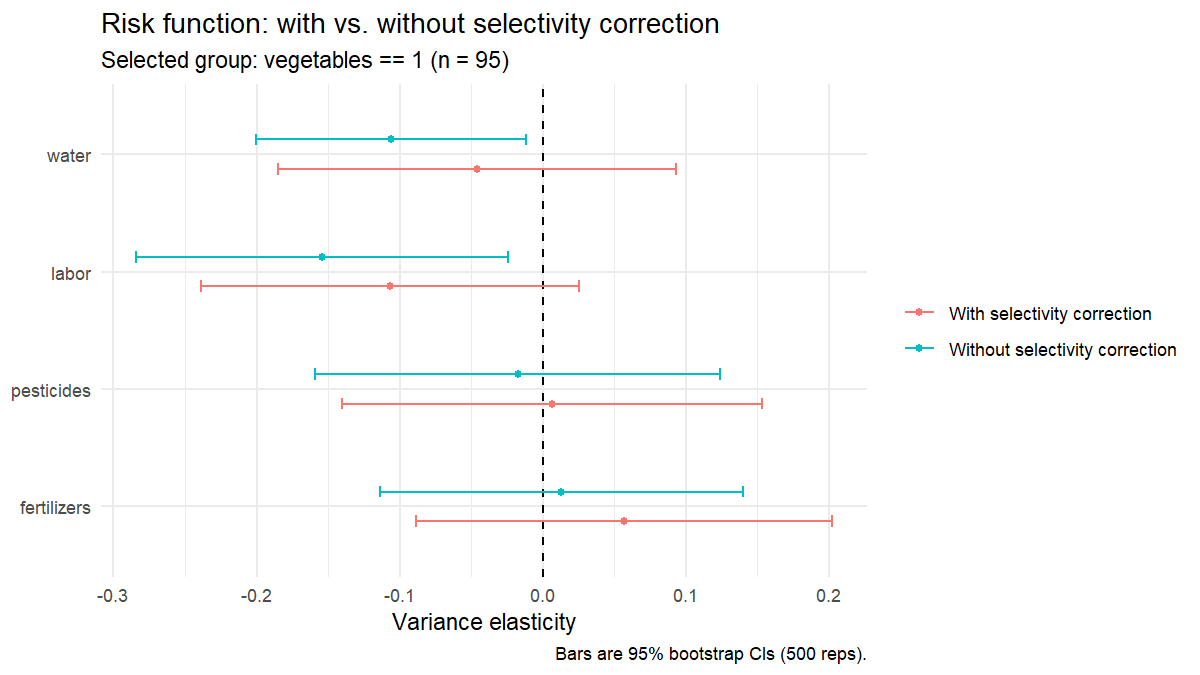
Quick example
library(JPselect)
farms <- simulate_kiti_data(seed = 42)
fit <- jp_fit(
data = farms,
selection_var = "vegetables",
selection_covariates = c("rainfall", "irrigated", "dist_town",
"dist_coast", "experience"),
output_var = "revenue",
input_vars = c("fertilizers", "pesticides", "labor", "water"),
shifter_vars = c("machinery", "rainfall", "irrigated",
"dist_town", "dist_coast", "experience"),
bootstrap_reps = 500
)
print(fit)
plot(fit)
jp_export(fit, "results.xlsx")Technical details
| Language | R (100%) |
| Key dependencies | stats, sandwich, ggplot2, openxlsx (for Excel export) |
| Standard errors | 500-replication nonparametric bootstrap that resamples the full pipeline (probit, IMR, mean function, residuals, risk function) on every replication. |
| License | MIT |
| Repository | github.com/robcareta/JPselect |
| Installation | remotes::install_github("robcareta/JPselect") |
| Status | First public release (v0.1.0) |
How to cite
If you use JPselect in published work, please cite the package together with the underlying paper.
Package:
Cardenas Retamal, R. (2026). JPselect: Just-Pope Production Functions with Heckman Selectivity Correction. R package version 0.1.0. https://github.com/robcareta/JPselect
Underlying paper:
Koundouri, P., & Nauges, C. (2005). On Production Function Estimation with Selectivity and Risk Considerations. Journal of Agricultural and Resource Economics, 30(3), 597-608.
In R, the canonical citations are also available via:
citation("JPselect")References
Heckman, J. (1979). Sample selection bias as a specification error. Econometrica, 47, 153-161. https://doi.org/10.2307/1912352
Just, R. E., & Pope, R. D. (1978). Stochastic representation of production functions and econometric implications. Journal of Econometrics, 7(1), 67-86. https://doi.org/10.1016/0304-4076(78)90006-4
Koundouri, P., & Nauges, C. (2005). On Production Function Estimation with Selectivity and Risk Considerations. Journal of Agricultural and Resource Economics, 30(3), 597-608. https://www.jstor.org/stable/40987295